There is a lot security professionals disagree on when it comes to Identity & Access Management (IAM). One thing most would agree on is that IAM means many things to many people, and has been shaped more by vendor product boundaries over the years than by overarching architectures, processes, and governance.
The basic term “Identity Management” (IdM) can be described very generally as an “administrative area that deals with identifying individuals in a system and controlling access to resources by placing restrictions on them” (source: Wikipedia). Well, turns out for most people IAM is pretty much the same as IdM – essentially an implementation of tools and processes that deal – at a basic level – with a mix of stuff:
- managing information about user identities (and their metadata, such as roles)
- managing information about resources/assets (often systems)
- providing user authentication, sometimes maybe with support for federation and single sign-on
- some kind of provisioning, for example setting up user accounts for individuals, or configuring a SAML proxy; provisioning often comes with some workflow automation support that also deals with changes and deprovisioning etc.
So why would an organization want IAM? There are a number of requirements that have to be met, especially: access to resources usually has to be restricted; regulatory requirements have to be met; audit/compliance need visibility into who should have access to what, who accessed what etc.; cost needs to be reduced through organizational efficiency, flexibility, and automation.
So far, so good – but really, to meet those requirements, more than the bullet list above needs to be done, and some of the assumptions about what comprises IAM need to be revisited:
Humans and machines
Firstly, in today’s interconnected world of devices, incl. Internet of Things (IoT) and bring your own (mobile) device (BYOD), IAM needs to support both human and machine users. Furthermore, IAM needs to go beyond provisioning (of user accounts etc.) and also focus on the often-neglected topic of restricting information flows between machines and/or users based on access policy.
Advanced access controls
Another complicating factor is that security policy requirements are getting increasingly complex, including “least privilege”, which – when you peel off the prevalent vendor snake oil – really means that access should only be granted for the “minimum necessary”. This is for example mandated by HIPAA. And this could mean that an access decision needs to be contextually figured out each time some user (human or machine) accesses a resource based on many, dynamically changing factors (e.g. role, task, geolocation, time of day etc.). It is important to distinguish statically administered user attributes such as roles from such dynamically changing factors. Many IAM vendors today offer a plethora of confusing and overlapping solutions that are often useful, but mostly misnamed as “dynamic role-based access control”, “ adaptive authentication” etc. What this really means is that additional context is baked into an access decision.
The conceptual issue is that there is an underlying assumption that access control is determined based on identities and context related to a user (individual) – which is often necessary but not sufficient: access control may also depend on other information, for example about the accessed resource or other context.
Many advanced access control approaches have been devised over the last 10-15 years to support such complexities, such as attribute-based access control (ABAC) – where (in simplistic terms) access is determined based on rules and attributes about requestors, resources, and context; risk-adaptive access control, where access changes based on calculated risk; proximity-based access control, business process based access control, history-based access control, model-driven security etc. (just to name a few).
At ObjectSecurity, we informally call all of those collectively “advanced access control approaches” (as for example implemented by ObjectSecurity OpenPMF). Like it or not, but IAM needs to also support such fine-grained, adaptive (information flow) access control. The access policies that are managed in IAM should be seen as the primary “master data” of the policy – it can either be directly implemented (using the IAM’s enforcement points), or synchronized/exported into other systems for enforcement.
For all the pentesters and whitehat hackers out there it is important that such access control approaches with enforcement points on many or all protected systems adds a lot of protection: maybe not so much on the system that gets hacked (because a software-based enforcement point can then be bypassed), but definitely by making “pivoting” to other systems much harder (because they enforce their own access policies).
Policy-based monitoring/logging
But protect/control is not all – we also need to focus on detect/respond. Unfortunately, as has been shown by the recent “Target hack”, current detect-and-respond approaches often fail because the well-intended tools are usually implemented without sufficient policy configurations. As a result, Security Incident and Event Management (SIEM) products produce way too many incidents for anyone to realistically get through and act upon within a useful timeframe (note that the “Target hack” SIEM detected the incident, but it was drowned out by hundreds of thousands of other incidents).
IAM needs to tie into monitoring and log aggregation to solve some of these issues: IAM’s incidents are usually more like “attempted policy violations”, for example if access to some information on some system was requested but denied in the specific context of the request. Knowing how such “white list” incidents relate to the policy makes it much easier for analysts to figure out criticality. Note that collecting other incidents the traditional way is also still necessary, but a lot of incidents can be discarded automatically thanks to the tie-in with the access policy.
Access federation and authentication federation
Federated identity management is a huge misnomer in IdM, and even federated access management usually is: What most products actually provide is “federated authentication management” based on cryptographic tokens that convey an authentication result. Turns out that this is different from actual “access federation”, sometimes referred to as “AuthoriZation Based Access Control” (ZBAC), and implemented – if done correctly – by using standards such as OAuth3. The idea is related but different from authentication federation in that the tokens provided by the access federation service are not tied to an authentication, but rather include permissions (authorizations) for the token holder. In the real-world the distinction would be (somewhat along the following lines):
- Authentication token: the use of a notary who certifies that a document is authentic (or a signature to have been made by the person claimed to be the signatory). The content of the certified document can be trusted as long as the notary is trusted.
- Access/Authorization token: A car unlocks with a car key. The car key is an authorization token, granting access to the car. Someone gives you a car key. The car does not care about who holds the car key as long as they hold the correct car key.
The assumption in both cases is that, as long as the producer of the token is trusted, the information conveyed in the token is also trusted.
The “soft” but almighty part of Identity & Access Management
Probably the most important aspects of IAM in any organization is not directly related to technology: the need for a clean IAM architecture, good IAM processes, and strong IAM governance (but the selected technology needs to support these). The idea is that the various parts of IAM (often many products) need to be brought together in a way that facilitates the central IAM management of “one truth of the data” – be it identities, assets, policies, logs, and workflows. Decentralized management should be avoided (this is where process and governance come into play!), and central IAM services should be used where possible (and some synchronization may still be needed for legacy systems).
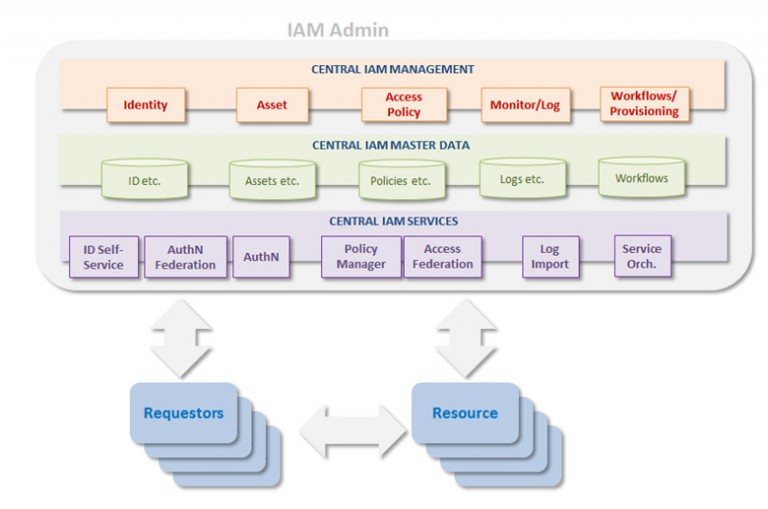
In conclusion
Getting IAM done for real requires that people are involved who deeply understand IAM – and esp. understand the need for the various capabilities I’ve described in this article: support for humans and machines, support for advanced access controls, support for policy-based monitoring/logging, and support for both access federation and authentication federation. And of course the “soft” but almighty part of IAM – strong architecture, processes, governance.
Do you want more information about OpenPMF, the Umbrella Platform for security policy management. Contact us here, or learn more on the OpenPMF product pages.